Blog/
Building a microservice application from Day 1
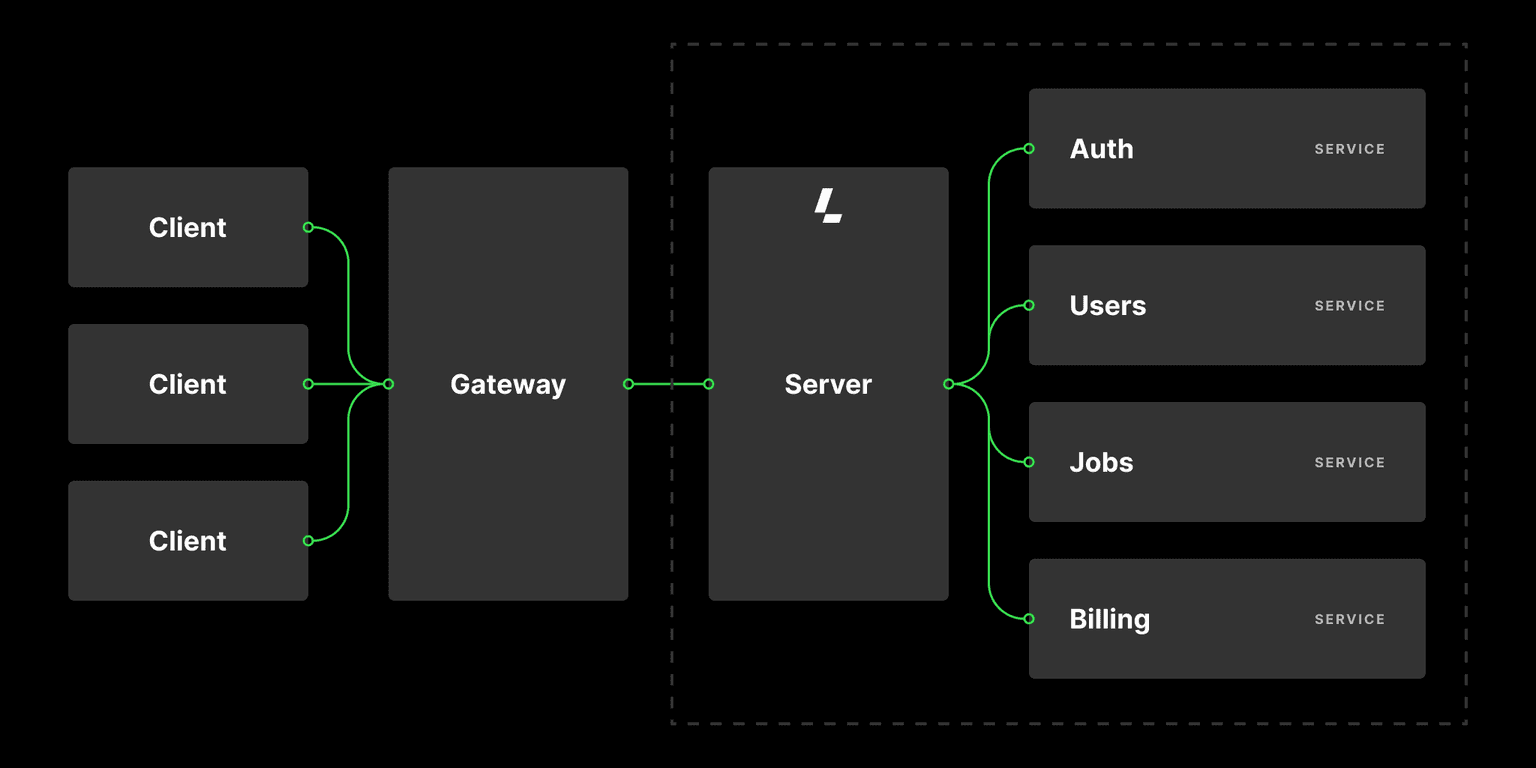
Microservice architecture is an exciting way to build applications, but it is not without its challenges. In reality, most developers start with a monolith and later break it into smaller pieces when the monolith can no longer scale vertically.
Unfortunately, this usually results in a suboptimal "microservice" architecture, which is just the same monolith distributed across multiple nodes.
But how do you build true microservices, and what tools do you need to ensure success?
There are a couple of things that you should know about true microservices: they must be isolated, meaning that a failure in one service doesn't cause a total failure of the application, and they should have a single responsibility, meaning that they should handle one aspect of the app.
The easiest way to ensure these constraints is by treating APIs as first-class citizens, which means treating the API spec as a contract.
Updating the spec should always come before working on new features or deprecating old ones. Building a microservice application then comes down to identifying the domains of responsibilities and designing APIs for services that fulfill each responsibility.
Ensuring that changes follow the same process can significantly reduce the risk of unexpected downtime and spiraling delivery estimations.
The Platform problem
Microservice development increases the Platform Engineering workload, which is a challenge in and of itself. Instead of deploying one app, you now have to support a cluster of services.
While there is a growing number of options to deploy these services, Kubernetes, although far from perfect, is the solution with the most significant market penetration that is proven to scale.
So, imagine you are a startup and want to deploy between 5 to 20 true microservices, each with its own isolated data store. What’s the most cost-effective strategy for accomplishing this?
Many engineers in this situation will reach for one of the large cloud providers, but this is frequently neither cost-effective nor performant.3
The experiment
One of our customers put together the following experiment to answer this question.
A single application (as simulated by 20 instances of the Nginx Docker container) will be run on a Kubernetes cluster in the US-East region of each provider.
This application will be tested via K6.io using 50 threads over 30 seconds from K6 Agents hosted in the US-East region.
To evaluate potential bottlenecks, the filesystem I/O performance will also be tested; for this, FIO will be used to run read/write tests using a 4 GiB file on a single node of the Kubernetes cluster.
We will target a monthly cost point in the range of $90-$180.
This experiment represents a moderate to large deployment for a single application in early-stage development. It could also be considered a reasonable proxy for a few instances of a smaller app on the same hardware, such as Dev, Staging, and QA instances.
In the experiment, they evaluated Latitude.sh, Amazon, DigitalOcean, Google, Linode, and Upcloud.
The results
While multi-node bare-metal clusters are likely too expensive for early-stage development, a single-node bare-metal cluster provides a good balance of raw throughput while retaining cost-effectiveness.
Although running a single-node cluster may feel excessive, it's far easier than attempting to build it on Docker Compose first and migrate later (or worse, trying to support both Compose and Kubernetes).
Here is the raw data:
Provider | Cost | Throughput (Average RPS) | Read (Average IOPS) | Write (Average IOPS) |
|---|---|---|---|---|
Amazon | $115 | 1037 | 2,300 | 769 |
Amazon | $90 | 1746 | 2,295 | 767 |
DigitalOcean | $131 | 698 | 82,242 | 27,484 |
DigitalOcean | $126 | 795 | 49,546 | 15,559 |
DigitalOcean | $168 | 919 | 81,465 | 27,229 |
DigitalOcean | $115 | 1038 | 47,447 | 15,865 |
$116 | 876 | 2,480 | 829 | |
$177 | 1209 | 4,814 | 1,609 | |
$97 | 1090 | 58,730 | 19,632 | |
$177 | 1631 | 68,616 | 22,951 | |
$137 | 1793 | 61,239 | 20,470 | |
$150 | 1343 | 69,408 | 23,201 | |
Linode | $160 | 960 | 90,766 | 30,340 |
Linode | $120 | 1511 | 37,931 | 12,675 |
Upcloud | $130 | 1501 | 49,697 | 16,608 |
These tests were made in low-end Latitude.sh instances from older generations, such as the c1.tiny.x86 and c2.small.x86, but it’s noticeable that Latitude.sh offers the best overall experience when considering both networking and file system throughput and the total cost of ownership.